Crowd Artificial Intelligence For Optimal Trading Strategies

Adventures with Microprediction
How To Use the Wisdom of AI Crowds to Find Optimal Trading Strategies
Financial markets are the ultimate laboratory for the Wisdom of Crowds. This is the concept that a group of people, competing to profit by predicting an outcome to be revealed in the future, can outperform even the most skilled individual predictor and deliver a result that is surprisingly close to the revealed truth. The idea was, as is well known, created by early English statistician Sir Francis Galton in his 1907 paper in Nature, Vox Populi.

A relative of Charles Darwin, he was the originator of regression analysis, the inventor of the use of fingerprints, and a pioneer in the statistical analysis of heredity, which lead to the more unsavory concepts of Eugenics.
The idea of the Wisdom of Crowds is compelling, if a little humbling, to those who, like me, have dedicated their careers to the concept of what
Peter Cotton calls “artisan data science.” Peter, who I first met when we were both working at JP Morgan, has a website where you can engage in the sport of time-series prediction via algorithms. He calls this process Microprediction, and it is a place where you can try out your predictive skills on time-series that update in real time. This is a distinction to the cold data on places like Kaggle, where you get to try again-and-again against the same dataset.

Finding Ex Ante Optimal Trading Strategies
For most of my career, I have been interested in two two key parts of systematic trading:
- finding a prediction of future asset prices, or alpha building; and,
- using those predictions for profit, which requires the construction of optimal trading strategies.
Most of the work one finds on the internet is directed at alpha building — particularly in this era of Deep Neural Networks and “A.I.” However, there is much to learn from the careful study of strategy design, a field called Stochastic Programming.
Mathematical Framework
A trader seeks to discover a policy function that tells them what to do. I generally call this the holding function as it represents the holdings you should have in response to your alpha to maximize your objective in expectation. The holding function may be expressed in terms of a stochastic information set

Here h are the holdings you currently have, α are your forecasts of the future returns of assets you are trading, and the final term represents other hyper- parameters that are inputs to your process.
The holding function is chosen by solving the stochastic programming problem
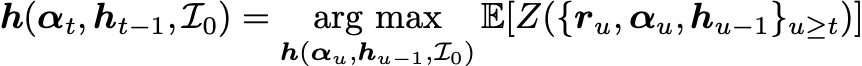
where Z is the performance statistic we seek to maximize over future time. In this expression the expectation is taken over the future distributions of returns, alphas, and holdings, and the optimization is done over the functional form of the holding function.
In discrete time the computation of the expectation above involves a high-dimensional multivariate integration

which is computationally quite a difficult expression to evaluate, either analytically or numerically. Some solutions are well known, and under special circumstances we can derive Mean Variance Optimization and other trading rules, but in general it’s a tough problem.
Finding Ex Post Optimal Trading Strategies
The Forgotten Problem
If the ex ante optimal strategy is hard to find, what about the ex post optimal strategy? Is that interesting to compute? Many quants would say no, in fact they would be stronger than that:
Quants would say that solving for the ex post optimal strategy is not only pointless, it demonstrates a fundamental misunderstanding of the relevant decision framework.
This is the traditional trader’s domain: asking “how much money was left on the table” after the trades are done and the positions were exited.
Ex Post Optimal Strategies
To do this we need to solve the following deterministic optimization problem:

This time there’s no consideration of “alpha,” because it’s irrelevant — we know the actual returns! This problem doesn’t deliver a policy function, it delivers a sequence of holdings that represent the absolute best we could have done graded by the statistic we choose to measure ourselves with, whatever that is: maximum gross profit, maximum net profit, Sharpe Ratio etc.
Solving this equation is still a computationally stiff one, but it is accessible to modern tools such as those available via the scipy.optimize package in Python, for example. Only the optimization phase is required, the multivariate integration can be ignored.
Utility Left on the Table
Solving this equation allows us to evaluate the performance that we actually achieved in comparison to the best we could have done. Perhaps we should call this “utility left on the table?”
Predicting Ex Post Optimal Holdings Ex Ante
In addition to grading our performance against the ideal, which in forecasting is called an oracle, there is something else we can do with this sequence of ex post optimal trades.
Suppose we were able to predict
in a causally legitimate manner? If we could find some suitable predictive function that satisfied
then we could use this g function to skip that whole messy multivariate integration and optimization step. For g would be a function that, in expectation, reproduced the oracle’s trading sequence from causal information. It would mean
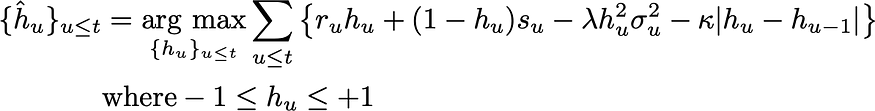
This would be a very useful function for a trader to possess! And the training set for this algorithm could be the observed sequence of ex post optimal holdings, h, as well as any other relevant information.
Tactical Asset Allocation
Consider investing into either a risky asset, R, with returns, r, or a safe asset, S, with returns, s. Canonical examples might be the whole market, as represented by the S&P 500 tracking ETF SPY, and some “risk free” instrument, as represented by the ETF BIL that holds a portfolio of U.S. short term Treasury Bills. Our “holding” in this scenario might be the proportion of capital invested into SPY, call that h, with the residual, 1–h invested into BIL.
Such an investment strategy is typically called Tactical Asset Allocation, and many Wall St. firms will sell you some version of this strategy. Typically the predictive function is created either by a bunch of quants, people like me, or by strategists who are employed to make statements about whether investors should allocate assets in a “risk on” manner (h=100%) or a “risk off” manner (h=0%), or somewhere in between.
Ex Post Optimal Tactical Asset Allocation
Looking back at sequences of returns, {r} and {s}, with transaction costs, κ, and volatility measures, {σ}, for a risk limited, risk averse, net profit maximizer the ex post optimal position sequence is the solution to

(I’ve extended the problem to allow shorting, although that is sometimes excluded from “classic” tactical asset allocation strategies, and I’m using either the VIX Index or the sample standard deviation of risk returns to supply the risk metric σ.)
The problem posed is a Linear-Quadratic Program with constraints and you can download the software necessary to solve it with two commands:$ pip install scipy
$ pip install scipy
$ pip install yfinance
The first one installs the scipy package, which allows access to an excellent general purpose optimizer scipy.optimize.maximize, and the second installs the yfinance package, which give access to real time asset pricing taken from the Yahoo! Finance website. (Professionals will need to use another source.)
Adventures with Microprediction
The Microprediction website is a venue where crowds of algorithms gather to try their hand at online prediction of various time series.
Anyone who publishes a time-series can see distributional predictions arrive, and the engines that make these predictions are scored every time a new value for the time-series is published. The algorithms are completely anonymous, only the owner knows who they are, but they are labelled by what
Microprediction calls Memorable Unique Identifiers, or MUIDs.
Here’s the distributional predictions generated by a set of algorithms for a time-series that I am publishing on the site (for the nature of that series, read on).

Some distributional forecasts from microprediction.org
The Microprediction Tactical Asset Allocation Streams
My initial approach to finding algorithms that could make predictions of ex post optimal holdings ex ante was to follow the approach of “artisan data science”: I invested CPU hours in solving LQ Programs of from long sequences of historic data and then started working with Deep Neural Nets to create predictive functions from the generated training data. But I realized that the Microprediction concept might provide a cheap way to shortcut all that work myself. If I could convert my training set into a stream of data that could be published on Microprediction then the crowds of algorithms congregated there might figure out what I was looking for, the predictive function g that approximates the solution to the “proper” stochastic programming problem that tells me what to hold.
Incremental Ex Post Optimal Positions
The fly-in-the-ointment with my approach, of course, is that these ex post optimal positions are only knowable for the past. This is the reason why quants generally ignore these calculations. You can’t make money from knowing what the right position to hold yesterday was, after all!
To get this to work it would be a necessary condition that the ex post optimal position computed now for the immediately prior hour coincide with, or at least be fairly close to, the position that would be computed when that hour was in the more remote past. i.e. That the optimal positions don’t drift much as time advances, or mathematically
In this expression the term on the left is what is feasible to compute without a time-machine and the term on the right represents the actual solution to the problem I’m trying to solve. Unless the relation is reasonably true, the idea I’m outlining here will be fruitless. I call the first term the incremental ex post optimal position and the latter the final ex post optimal position.
Predicting at Leads more than Zero
Of course the easiest way to predict the incremental ex post optimal position would be to solve the optimization problems I’ve outlined immediately before the next value is published to the Microprediction website. That will delivery high predictive accuracy which, unfortunately, has zero economic value.
In finance we need prices to change for value to be created and they don’t change much over very small intervals. If we compute these ex post optimal positions with an hourly cadence, for example, then predicting what value will be computed an hour from now is much more interesting, and potentially more economically valuable, than predicting the value that will be computed almost immediately.
The Microprediction Streams
I’m running some experiments with Microprediction. To publish data there all you have to do is compute a cryptographic key with at least a given level of difficulty. (You might think of this computation as similar to mining a cryptocurrency, although the token you are creating has tangible value as it is giving you the ability to publish data. The tokens that allow you to publish are harder to compute than those that allow you to predict other published data.) To do that, do this (it takes several hours of computation):$ pip install microprediction
$ python3
>>> from microprediction import new_key
>>> my_key=new_key(difficulty=12)
The streams I’m publishing contain the solutions to incremental Tactical Asset Allocation problems computed for a range of risk assets. They are:
- the S&P 500 Index versus 91 day U.S. Treasury bills;
- the SPY ETF versus the BIL ETF, known as the “equity” or “consumer” stream;
- the USO ETF versus BIL, a/k/a the “energy” stream since USO is linked to the price of crude oil;
- the TLT ETF versus BIL, a/k/a the “curve” stream since TLT is linked to holding long positions in U.S. Ten Year Treasury Notes and BIL is linked to Three Month Treasury Bills;
- the returns of bitcoin versus the BIL ETF, known as the “crypto” stream.
A screenshot of the data on the Microprediction website is shown below:

The “crypto” T.A.A. stream from Microprediction.org
Experimental Results
I’ve undertaken this work because I think it is a potentially very interesting way to “shortcut” the laborious and imprecise ways we currently use to solve the stochastic programming problems we are presented with as systematic traders. I don’t know whether this will work, and certainly the data as published does not represent investment advice as it is only informative about the past. (Indeed, any investment strategy you engage in should be adapted to your own personal situation, you may benefit from consulting a professional advisor, and ultimately is done at your own risk.)
The goal of this work is to answer the question:
is this a useful way to analyze a familiar problem?
Do Incremental Ex Post Optimal Positions Agree with Final Ex Post Optimal Positions?
Clearly we cannot compute fully ex post optimal positions, because that can only be done “at the end of time.” But we can track how they evolve through time and study the relationship of
This is shown for the “equity” stream in the figure below:

So the assumption that these quantities are similar is well supported by the data.
Does the Forecasting Crowd Possess Positive Forecasting Skill?
This, of course, is the key question and the answer is that we do not yet have enough data to answer the question in a statistically meaningful way.

The data shows a weak positive correlation between the expected value of of the next data point, computed by downloading the crowd’s CDF for the series for predictions of lead at least 3555 seconds, and the data that was subsequently published.
Next Steps
I think this approach is sufficiently interesting to keep at it. I am a big believer in the Wisdom of Crowds and, even though it goes against the grain of every proprietary trader out there, that other people might be better at the job of predicting returns than I am. As I run these systems I am gathering the data necessary to answer the key question:
Can a causally legitimate predictive function, g, for the holding function, h, be discovered by a crowd of competing algorithms?
I will post the results here as they come in.
If you like this article and would like to read more of my work, consider my book Adventures in Financial Data Science which is available as an eBook for Kindle, and also from Apple Books and Google Books. A revised second edition will be published by World Scientific.